
Recently updated on May 20, 2025
Introduction or “What problem are we solving?”
This article aims to illustrate how to create a Lego of reusable building blocks for streamlining the development of smart bots powered by large language models (LLMs). We’ll explore how to build such a Lego utilizing features provided by Langchain4j v.0.28.0, a framework tailored to speed up the development of LLM-powered Java applications.
We’ll walk you through the process of a bot integration with the Retrieval-Augmented Generation (RAG) infrastructure. This approach extends LLM’s conversational capabilities by allowing them to access specific domains or an organization’s internal knowledge base. By seamlessly incorporating RAG, the chatbot gains the power to retrieve and leverage the most up-to-date and relevant information without the need for retraining.
By leveraging RAG, we’ll be able to transform several use cases:
- “Enhanced Conversational Agent” to make conversations efficient, personalized, and accurate. This could be used in customer support bots, educational tutors, or virtual assistants, providing them with the ability to use specific data.
- “Knowledge-base Explorer” for domains where large volumes of documents need to be analyzed and referenced, RAG can automate and enhance the process of finding relevant case law, precedents, etc. In this case, RAG can augment data with additional information from external sources or databases, thereby assisting professionals in making informed decisions.
- “Question Answering System”, like a company policy explorer, where RAG can significantly improve such systems by fetching relevant documents or data snippets to provide precise, accurate answers to user queries. This is especially useful for fact-based questions where up-to-date information is crucial.
Our code examples, provided in this article, primarily focus on the bot’s text modality.
Prerequisites
Before we begin, make sure you have the following:
- Telegram bot name and token registered using Telegram Botfather.
- LLM API access:
- API key (like OpenAI API Key) for LLMs supported AIaaS (like OpenAI , Azure OpenAI, Azure OpenAI, etc.)
- Locally installed LLM (like LocalAI , Ollama etc.) with corresponding models shown in the picture below
Step 1: Creating a Spring Boot project
To begin building our chatbot we need to properly configure the development environment. Let`s start with creating a Spring Boot project and including some of the necessary dependencies:
- Create a Spring Boot 3.2.1 Maven project using, for example, Spring Initializr.
- Add telegram bot 6.9.7.1 support
- Add Langchain4j 0.28 Maven dependencies. We can start our journey with langchain4j, langchain4j-open-ai, langchain4j-ollama, langchain4j-pdf-parser, langchain4j-apache-poi-parser
- Feel free to add other dependencies like Lombok, org.slf4j, commons-io, Springdoc openapi, etc.
Step 2: Configuring LLM
LLM parameters configuration
To configure model parameters for our project, we will use an externally configurable Builders (via application.properties or application.yml)
AiaaS models
For such types of models, externally configurable Builder OpenAIChatLanguageModelBuilder could look like the code below:
@Service
@Slf4j
public class OpenAIChatLanguageModelBuilder extends
OpenAIChatModelBuilderParameters
implements ChatModelBuilder {
@Override
public ChatLanguageModel build() {
ChatLanguageModel chatLanguageModel = OpenAiChatModel.builder()
.apiKey(OPENAI_API_KEY)
.modelName(gptModelName)
.timeout(ofSeconds(timeoutSec.longValue()))
.logRequests(logRequests.booleanValue())
.logResponses(logResponses.booleanValue())
.maxRetries(maxRetries)
.temperature(temperature)
.build();
return chatLanguageModel;
}
. . .
}inheriting from a parent OpenAIChatModelBuilderParameters class, like:
public abstract class OpenAIChatModelBuilderParameters extends BaseChatModelBuilderParameters {
@Value("${OPENAI_API_KEY}")
String OPENAI_API_KEY;
@Value("#{new Boolean('${GPT.log.requests}')}")
Boolean logRequests;
@Value("#{new Boolean('${GPT.log.responses}')}")
Boolean logResponses;
...inheriting from the code below accordingly:
public abstract class BaseChatModelBuilderParameters {
@Value("${GPT.modelName}")
String gptModelName;
@Value("#{new Integer ('${GPT.maxRetries}')}")
Integer maxRetries;
@Value("#{new Long ('${GPT.timeout.sec}')}")
Long timeoutSec;
@Value("#{new Double ('${GPT.temperature}')}")
Double temperature;
...Similarly, we can add some useful parameters like organization ID and seed, aimed at increasing AiaaS model determinism, etc.
On-premise deployable models
Likewise, a corresponding ChatModelBuilder (for on-premise deployable models like Ollama) could look like this:
@Service
@Slf4j
public class OllamaChatModelBuilder extends LocalChatModelBuilderParameters
implements ChatModelBuilder {
@Override
public ChatLanguageModel build() {
ChatLanguageModel model = OllamaChatModel.builder()
.baseUrl(baseURL) //http://localhost:11434
.modelName(gptModelName)//phi, "orca-mini"
.maxRetries(maxRetries)
.timeout(ofSeconds(timeoutSec))
.temperature(temperature)
.build();
return model;
}
. . .
}inheriting from a parent LocalChatModelBuilderParameters class, like
public abstract class LocalChatModelBuilderParameters
extends BaseChatModelBuilderParameters{
@Value("${GPT.baseURL}")
String baseURL;
. . .
}During this step, keep attention on the following details:
- The key difference between builders for on-premise and AIaaS models is baseURL support
- Both OllamaChatModelBuilder and OpenAIChatLanguageModelBuilder build ChatLanguageModel- the same abstraction for different language models.
Chat Memory Configuration
For a simple scenario, we have two options: TokenWindowChatMemory, and MessageWindowChatMemory.
TokenWindowChatMemory operates as a sliding window of maxTokens tokens. It retains as many of the most recent messages as can fit into the window. If there isn’t enough space for a new message, the oldest one (or multiple) is discarded.
MessageWindowChatMemory operates as a sliding window of maxMessages messages. It retains as many of the most recent messages as can fit into the window. If there isn’t enough space for a new message, the oldest one is discarded.
In our project, we will use externally configurable MessageWindowChatMemory in the following way:
@Service
@Slf4j
public class MessageWindowChatMemoryBuilderImpl implements MessageWindowChatMemoryBuilder {
@Value("${chat.system.message}")
String systemMessage;
@Value("#{new Integer ('${chat.memory.maxMessages}')}")
Integer maxMessages;
@Override
public MessageWindowChatMemory build() {
MessageWindowChatMemory memory = MessageWindowChatMemory.withMaxMessages(maxMessages);
String text = new String(systemMessage);
SystemMessage systemMessage = SystemMessage.from(text);
memory.add(systemMessage);
return memory;
}
}Keep attention on externally configured SystemMessage, typically used to instruct LLM regarding the AI’s actions, such as its behavior or response style.
Lanchain4j RAG Overview
Langchain4j framework provides built-in support for RAG ingestion and retrieval chains.
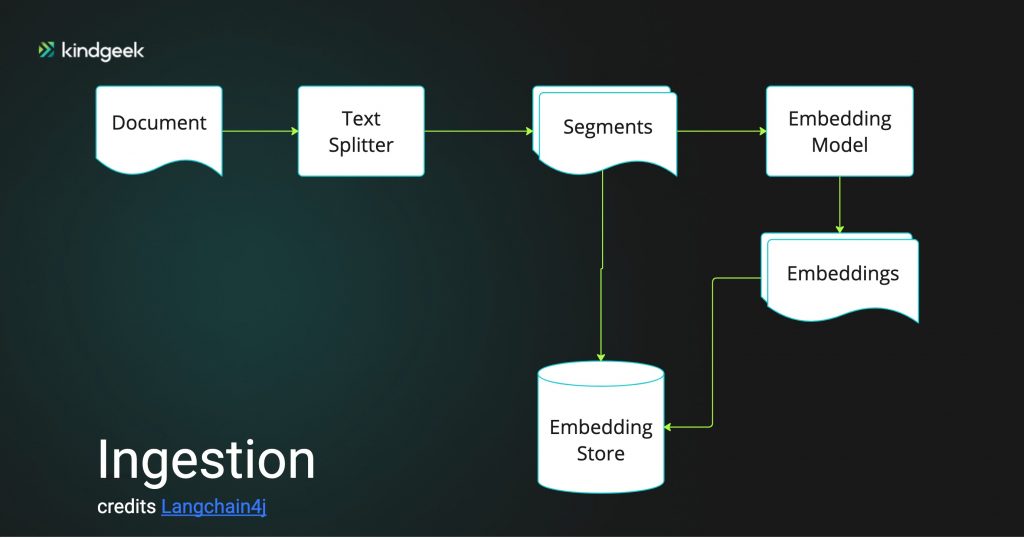
The first step of the ingesting chain is document loading and parsing, aimed to achieve Document representation independent of the original location and format. Langchain4j provides DocumentLoader for loading documents (using Document representation) from many sources (S3 bucket , Azure Blob storage, Tencent Cloud Object Storage , GitHub, websites, filesystem) in different formats (text, HTML, PDF, Microsoft documents).

The next step is splitting (or chunking) a Document into a List<TextSegment>. Vector embeddings will be calculated using EmbeddingModel for each segment and then stored in some vector database. EmbeddingModel interface wraps different implementations like OpenAiEmbeddingModel,
AzureOpenAiEmbeddingModel, OllamaEmbeddingModel etc., aimed to convert words, sentences, or documents into embeddings. We will use a popular sentence-transformers embedding model, all-MiniLM-L6-v2, as it can run within our Java application’s process.
Actually, Langchain4j supports a broad selection of vector databases wrapped by the EmbeddingStore<Embedded> interface:
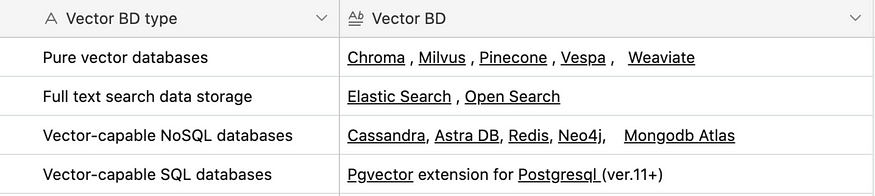
InMemoryEmbeddingStore<Embedded>, which stores embeddings in memory, is also worth mentioning as a useful rapid prototyping instrument.
In our project, we will use Pgvector for Postgresql v.15, so after Pgvector extension installation (via CREATE EXTENSION vector), we will be able to use vector type and vectors table:
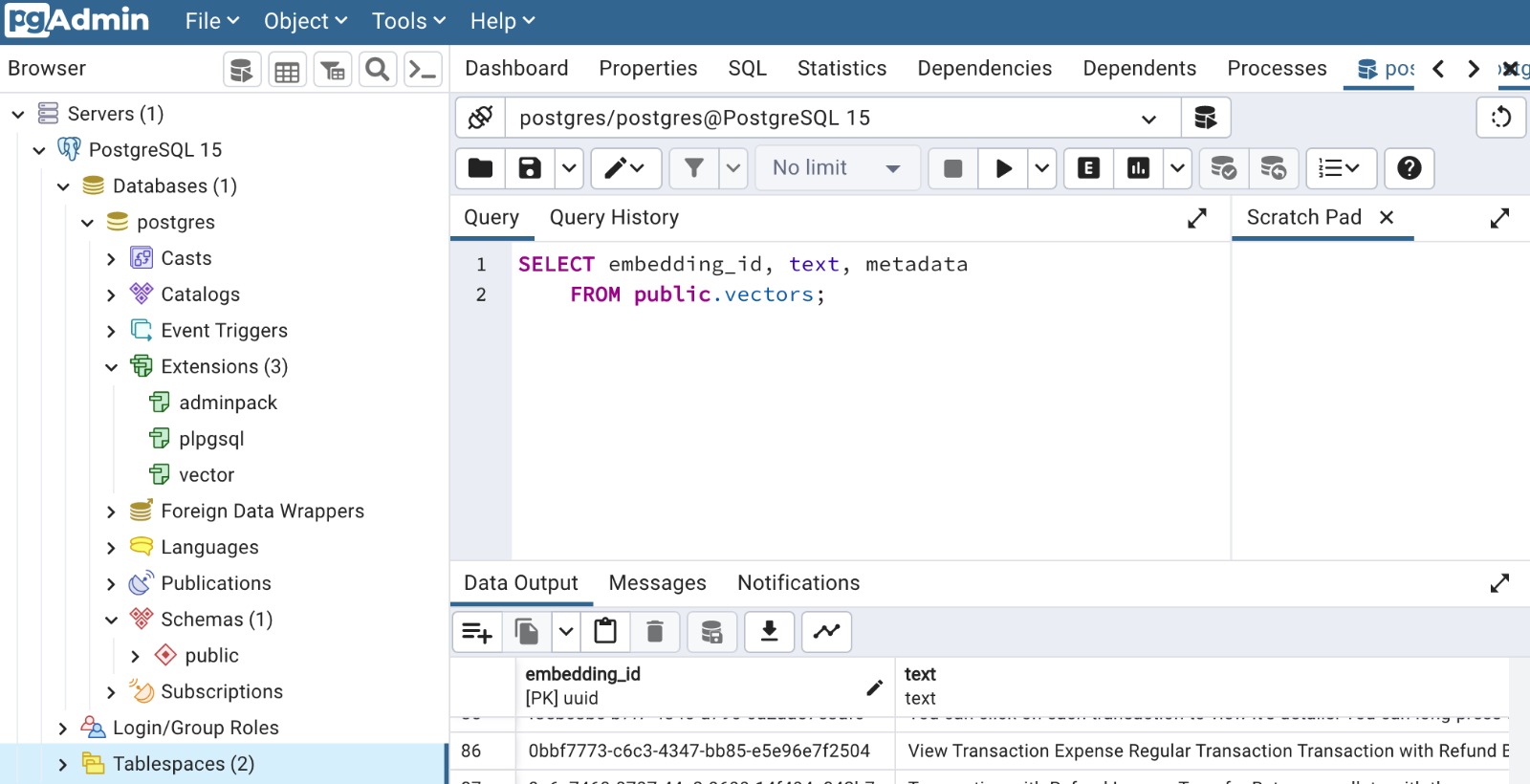
During this step, don`t forget:
- To add Langchain4j-pgvector Maven dependency
- To add Pgvector configuration parameters into your application properties, like shown here:
@Service
@RequiredArgsConstructor
@Slf4j
public class EmbeddingStoreServiceBuilderImpl implements EmbeddingStoreServiceBuilder {
@Value("${pgvector.host}")
private String host;
@Value("#{new Integer ('${pgvector.port}')}")
private Integer port;
@Value("${pgvector.user}")
private String user;
@Value("${pgvector.password}")
private String password;
@Value("${pgvector.database}")
private String database;
@Value("${pgvector.table}")
private String table;
@Value("#{new Boolean('${pgvector.droptable}')}")
private Boolean dropTableFirst;
@Value("#{new Boolean('${pgvector.useindex}')}")
private Boolean useIndex;
@Value("#{new Integer ('${pgvector.dimension}')}")
private Integer dimension;
public EmbeddingStore<TextSegment> build() {
EmbeddingStore<TextSegment> embeddingStore = PgVectorEmbeddingStore
.builder()
. . .Once our data have been ingested into the EmbeddingStore<Embedded>, a bot user can query relevant information.
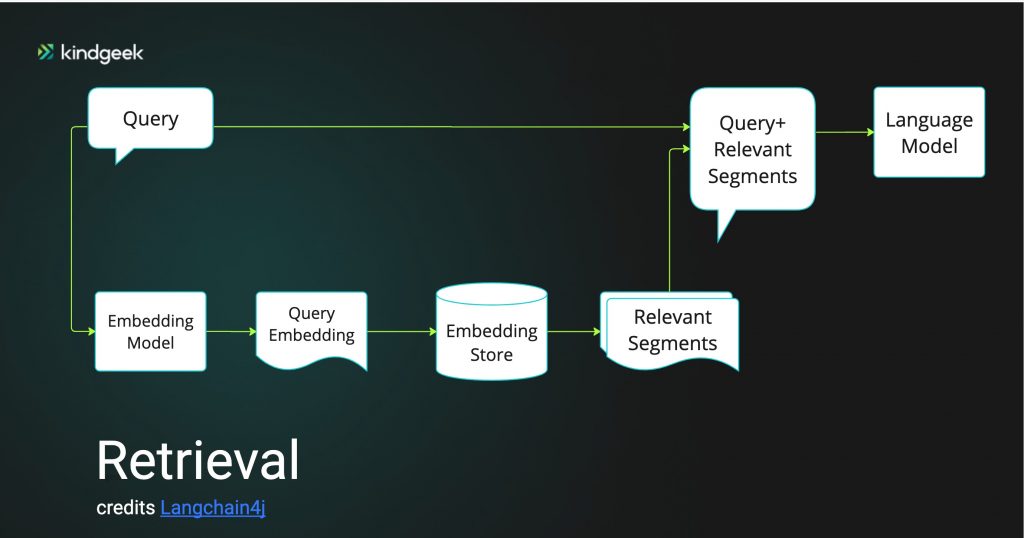
Langchain4j release 0.28.0 supports several retrieval scenarios:
- Naive RAG via ConversationalRetrievalChain
2. Advanced RAG:
- Based on query compression
- Based on using query routing to direct a user query to the most appropriate EmbeddingStore<Embedded>, in a case when a knowledge base is spread across multiple sources
- Based on reranking API supported by Cohere
In our project, we will use retrieval based on a query compression approach.
Step 3: Implement an ingesting infrastructure
Parsing
File parsing aims to obtain a Document abstraction by removing original format-specific data and remaining the unstructured content of a single file:
public Document parse(Path documentPath) {
String extension = getFileExtension(documentPath);
DocumentParser documentParser;
switch (extension) {
case "pdf":
documentParser = new ApachePdfBoxDocumentParser();
break;
case "doc", "xlsx", "docx", "xls", "ppt", "pptx":
documentParser = new ApachePoiDocumentParser();
break;
default:
documentParser = new TextDocumentParser();
}
return document = FileSystemDocumentLoader.loadDocument(documentPath, documentParser);
}It is important to note that in HTML case, we need to clear markup using HtmlTextExtractor, like in the following way:
public Document extractHtmL(String urlString) {
URL url = formUrl(urlString);
Document htmlDocument = UrlDocumentLoader.load(url, new TextDocumentParser());
HtmlTextExtractor transformer = new HtmlTextExtractor(null, null, true);
Document transformedDocument = transformer.transform(htmlDocument);
return transformedDocument;
}Splitting and Ingesting
For generic text splitting, Langchain4j recommends using recursive DocumentSplitter. It tries to split the document into paragraphs first and fits as many paragraphs into a single TextSegment as possible. If some paragraphs are too long, they are recursively split into lines, then sentences, then words, and then characters until they fit into a segment. The code below illustrates what recursive DocumentSplitter could look like, how to use EmbeddingModel like all-MiniLM-L6-v2, and how to store List<Embedding> and List<TextSegment> into our Pgvector store.
The code also illustrates how to add externally configurable parameters for DocumentSplitter:
- Integer maxSegmentSizeInChars — The maximum size of the segment, defined in characters.
- Integer maxOverlapSizeInTokens — The maximum size of the overlap, defined in characters.
@NonNull
private final EmbeddingStoreServiceBuilder embeddingStoreServiceBuilder;
@NonNull
private final EmbeddingModelBuilder embeddingModelBuilder;
@Value("#{new Integer ('${openai.document.splitter.maxSegmentSizeInChars}')}")
Integer maxSegmentSizeInChars;
@Value("#{new Integer ('${openai.document.splitter.maxOverlapSizeInTokens}')}")
Integer maxOverlapSizeInTokens;
public void IngestDocument(Document document) {
IngestDocument(document, maxSegmentSizeInChars, maxOverlapSizeInTokens);
}
public void IngestDocument(Document document, Integer maxSegmentSize, Integer maxOverlapSize) {
EmbeddingModel embeddingModel = embeddingModelBuilder.build();
EmbeddingStore<TextSegment> pgVectorEmbeddingStore = embeddingStoreServiceBuilder.build();
DocumentSplitter splitter = DocumentSplitters.recursive(maxSegmentSize, maxOverlapSize);
List<TextSegment> segments = splitter.split(document);
log.debug("Text segments: {} {}", segments);
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
pgVectorEmbeddingStore.addAll(embeddings, segments);
log.debug("Ingested document : {}", document);
}Step 4: Implement retrieval infrastructure
Compressing Query
This technique is a way of reducing the noise in the retrieved documents by “compressing” irrelevant information. The idea behind this method goes back to RECOMP and LLMLingua publications.

image credits RECOMP
Query compression involves taking the user’s query and the preceding conversation, then asking the LLM to “compress” it into a single, self-contained query. Thus, the method adds a bit of latency and cost but could significantly enhance the quality of the RAG process. It’s worth noting that the LLM used for compression doesn’t have to be the same as the one used for conversation. For instance, you might use a local Small Language Model (SLM), like Orca 2 (7B & 13B) for summarization.
image credits Orca2
In Langchain4j, query compression is implemented as PromptTemplate aimed to summarize the state of chat memory, user query and relevant information retrieved from EmbeddingStore. The code below shows the default summarization PromptTemplate:
"Read and understand the conversation between the User and the AI. " +
"Then, analyze the new query from the User. " +
"Identify all relevant details, terms, and context from both the conversation and the new query. " +
"Reformulate this query into a clear, concise, and self-contained format suitable for information retrieval.\n" +
"\n" +
"Conversation:\n" +
"{{chatMemory}}\n" +
"\n" +
"User query: {{query}}\n" +
"\n" +
"It is very important that you provide only reformulated query and nothing else! " +
"Do not prepend a query with anything!"Configure Content Retriever
We will use externally configured thresholds to define the “level of information relevance” in the following way:
@Slf4j
@RequiredArgsConstructor
public class ContentRetrieverBuilderImpl implements ContentRetrieverBuilder {
private final EmbeddingStoreServiceBuilder embeddingStoreServiceBuilder;
private final EmbeddingModelBuilder embeddingModelBuilder;
@Value("#{new Double ('${rag.contentRetriever.minScore}')}")
Double minScore;
@Value("#{new Integer ('${rag.contentRetriever.maxResults}')}")
Integer maxResults;
@Override
public ContentRetriever build() {
EmbeddingStore embeddingStore = embeddingStoreServiceBuilder.build();
EmbeddingModel embeddingModel = embeddingModelBuilder.build();
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(maxResults)
.minScore(minScore)
.build();
return contentRetriever;Where:
- The threshold configuration could look like this:
rag.contentRetriever.maxResults=3
rag.contentRetriever.minScore=0.59- EmbeddingStoreServiceBuilder builds pgVectorEmbeddingStore
- EmbeddingModelBuilder builds all-MiniLM-L6-v2 as described earlier (see Step 3 for details)
Step 5: Integration of LLM-powered building blocks with the Telegram bot
Define Completion Interfaces
ChatService interface is straightforward, supporting both completion modes: synchronous and asynchronous.
public interface ChatService {
String chat(String message);
TokenStream chatTokenStream(String message);
}“Synchronous (or blocking) completion” means that when our bot sends a request to the LLM API, it waits for the operation to complete and the API to return the response before proceeding with any further actions.
“Asynchronous (or streaming) completion” refers to a non-blocking interaction pattern with LLM API, such as OpenAI’s API, where the application does not wait for the API call to complete. LLM instead sends a response partially as a token stream of the response as they are ready.
It is important to note that:
- Not all LLM’s API support “Asynchronous completion”,
- “Asynchronous completion” integration with the Telegram bot, as will be shown below, is quite tricky and challenging
- Synchronous completion is comparably simpler but less user-friendly
Integrate Completion Interfaces into Telegram bot
We can start coding our Telegram bot by extending well-known TelegramLongPollingBot, by adding externally configured botUsername, botToken and implementing onUpdateReceived method. Obviously, we also have to implement our listener of ApplicationReadyEvent aimed to register our bot after starting our Spring Boot Application. As shown below, the sending of Telegram messages is encapsulated in the following TelegramSenderService:
@Component
@RequiredArgsConstructor
@Slf4j
public class TelegramBot extends TelegramLongPollingBot implements ApplicationListener<ApplicationReadyEvent> {
private final TelegramSenderService telegramSenderService;
@Value("${telegram.bot.name}")
private String botUsername;
@Value("${telegram.bot.token}")
private String botToken;
@Override
public void onUpdateReceived(Update update) {
log.debug("Update object {}", update);
String question;
if (update.hasMessage() && update.getMessage().hasText()) {
String message_text = update.getMessage().getText();
long chat_id = update.getMessage().getChatId();
telegramSenderService.sendMessage(chat_id, question);
}
}
@Override
public void onApplicationEvent(@NotNull ApplicationReadyEvent event) {
try {
TelegramBotsApi botsApi = new TelegramBotsApi(DefaultBotSession.class);
botsApi.registerBot(this);
} catch (TelegramApiException e) {
log.error("Failed to register telegram bot", e);
}
}
@Override
public String getBotUsername() {
return botUsername;
}
@Override
public String getBotToken() {
return botToken;
}
}TelegramSenderService: “Synchronous completion” case
On the code below, it is worth paying attention to:
- parseMode
- sendTypingEffect method
The parseMode is useful in cases where LLM answers to query using Markdown. As is known, LLMs like OpenAI gpt-4 , Ollama gemma are able to answer using Markdown syntax. For such models we can configure our application in the following way:
telegram.bot.parsemode=MarkdownThe sendTypingEffect method enhances user experience via “simulation of typing” as a reaction to a user query.
@Slf4j
@Service
public class TelegramSenderServiceImpl extends DefaultAbsSender implements TelegramSenderService {
private final ChatService chatService;
@Value("${telegram.bot.parsemode:#{null}}")
private String parseMode;
@Override
public void sendMessage(Long chatId, String text) {
sendTypingEffect(chatId);
sendMessage(chatId, chatService.chat(text), parseMode);
}
protected TelegramSenderServiceImpl(@Value("${telegram.bot.token}") String botToken, ChatService chatService) {
super(new DefaultBotOptions(), botToken);
this.chatService = chatService;
}
private void sendMessage(Long chatId, String text, String parseMode) {
SendMessage message = new SendMessage();
message.setChatId(String.valueOf(chatId));
message.setParseMode(parseMode);
message.setText(text);
log.debug("Message to send {} ", message);
try {
execute(message);
} catch (TelegramApiException e) {
log.error("TelegramApiException", e);
}
}
private void sendTypingEffect(Long chatId) {
SendChatAction chatAction = new SendChatAction(chatId.toString(), ActionType.TYPING.name(), null);
try {
execute(chatAction);
} catch (TelegramApiException e) {
log.error("TelegramApiException", e);
}
}
. . .TelegramSenderService: “Streaming completion” case
“Streaming completion” implementation using Telegram API is based on the following:
- It is useless and irrational to send to Telegram each string received from TokenStream chatTokenStream(String message) in response to the user query. A Telegram screen would be really impractical for the user as it would contain isolated messages with different headers and time stamps
- To avoid this issue, we came up with the idea of tokens buffering by grouping a portion of tokens and updating it as the same message with the same header and timestamp. To implement this approach, we can use the following method:
public void updateMessage(Long id, Integer msgId, String what) {
EditMessageText editMessageText = EditMessageText.builder()
.chatId(String.valueOf(id))
.messageId(msgId)
.text(what)
.parseMode(parseMode)
.build();
log.debug("Edited message to send {} ", editMessageText);
try {
execute(editMessageText);
} catch (TelegramApiException e) {
log.error("Message is not edited.", e);
}
}- The challenge here is the risk of receiving Telegram API error 429. To minimize such a risk, we have to organize a“delay” between sending our buffered portion of tokens and receiving from TokenStream
The implementation idea is shown in the picture below
So, we could implement our vision in the following way:
- Changing one line of code of onUpdateReceived method of TelegramBot:
— from telegramSenderService.sendMessage(chat_id, question);
— to telegramSenderService.streamMessageToBot(chat_id, question);
- Adding configurable size of buffered portion of tokens
- Adding configurable “delay” between sending such a buffered portion
@Value("${telegram.bot.amountChunk:#{10}}")
private Integer amountChunk;
@Value("${telegram.bot.waiting:#{600}}")
private Long waiting;- Implementing dedicated StreamingResponseHandler<AiMessage>()with onNext onComplete and onError methods
@Override
public void streamMessageToBot(Long chatId, String question) {
AtomicBoolean isFirst = new AtomicBoolean(true);
AtomicReference<String> resultAnswerText = new AtomicReference<>(StringUtils.EMPTY);
AtomicInteger loadedChunks = new AtomicInteger(0);
AtomicReference<Message> message = new AtomicReference<>();
sendTypingEffect(chatId);
TokenStream answer = chatService.chatTokenStream(question);
answer
.onNext(chunk -> aiChunkMessageConsumer(chunk, chatId, isFirst, resultAnswerText, loadedChunks, message))
.onComplete(aiMessageResponse -> completeConsumer(loadedChunks.get(), message.get(), resultAnswerText.get(), aiMessageResponse.content().text()))
.onError(this::errorConsumer)
.start();
}- Implementing aiChunkMessageConsumer responsible for chunks buffering like in the following code
private void aiChunkMessageConsumer(String chunk, Long chatId, AtomicBoolean isFirst, AtomicReference<String> resultAnswerText,
AtomicInteger loadedChunks, AtomicReference<Message> message) {
if (StringUtils.isNotBlank(chunk)) {
if (isFirst.get()) {
sendFirsChunkOfAnswer(chunk, chatId, isFirst, resultAnswerText, message);
} else {
updateMessageByNextChunkOfAnswer(chunk, chatId, loadedChunks, resultAnswerText, message);
}
}
}
private void sendFirsChunkOfAnswer(String chunk, Long chatId, AtomicBoolean isFirst,
AtomicReference<String> resultAnswerText,
AtomicReference<Message> message) {
Message returnedMessage = sendMessageWithReturn(chatId, chunk, parseMode);
if (returnedMessage == null) {
return;
}
message.set(returnedMessage);
isFirst.set(false);
resultAnswerText.set(resultAnswerText.get() + chunk);
}
private void updateMessageByNextChunkOfAnswer(String chunk, Long chatId, AtomicInteger loadedChunks,
AtomicReference<String> resultAnswerText,
AtomicReference<Message> message) {
var msg = message.get();
resultAnswerText.set(resultAnswerText.get() + chunk);
loadedChunks.set(loadedChunks.get() + 1);
log.debug("Loaded chunks: {}", loadedChunks.get());
if (loadedChunks.get() == amountChunk) {
sendTypingEffect(chatId);
updateMessage(msg.getChatId(), msg.getMessageId(), resultAnswerText.get());
loadedChunks.incrementAndGet();
loadedChunks.set(0);
sleep(waiting);
}
}- Implementing a “Delay” between sending is quick and simple:
private void sleep(Long duration) {
try {
Thread.sleep(duration);
} catch (InterruptedException e) {
log.error("Failed to register telegram bot", e);
}
}Implement Completion Interfaces
To implement described above completion interfaces, firstly we have to define two low-level interfaces: Assistant and StreamingAssistant
public interface Assistant {
String chat(String message);
}public interface StreamingAssistant {
@SystemMessage({
"You are a customer support agent and personal financial adviser.",
"Today is {{current_date}}."
})
TokenStream chat(String message);
}Secondly, we have to initialize our assistance using several builders explained above (see Step 1 — Step 3 sections)
public class ChatServiceImpl implements ChatService {
private final OllamaChatModelBuilder ollamaChatModelBuilder;
private final OpenAIChatLanguageModelBuilder chatLanguageModelBuilder;
private final StreamingChatModelBuilder streamingChatModelBuilder;
private final MessageWindowChatMemoryBuilder messageWindowChatMemoryBuilder;
private final ContentRetrieverBuilder contentRetrieverBuilder;
private final ImageModelBuilder imageModelBuilder;
private final ToolProvider toolProvider;
private StreamingAssistant streamingAssistant;
private Assistant assistant;
private void initAssistant() {
ChatLanguageModel
chatLanguageModel = chatLanguageModelBuilder.build();
ContentRetriever contentRetriever = contentRetrieverBuilder.build();
/**
Creating a CompressingQueryTransformer, which compresses the user's query
and the preceding conversation into a single, stand-alone query.
*/
QueryTransformer queryTransformer = new CompressingQueryTransformer(chatLanguageModel);
/**
RetrievalAugmentor as the entry point into the customisable RAG flow in LangChain4j
according to your requirements.
*/
RetrievalAugmentor retrievalAugmentor = DefaultRetrievalAugmentor.builder()
.queryTransformer(queryTransformer)
.contentRetriever(contentRetriever)
.build();
messageWindowChatMemory = messageWindowChatMemoryBuilder.build();
assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(chatLanguageModel)
.chatMemory(messageWindowChatMemory)
.tools(toolProvider)
.retrievalAugmentor(retrievalAugmentor)
.build();
StreamingChatLanguageModel streamingChatModel = streamingChatModelBuilder.build();
streamingAssistant = AiServices.builder(StreamingAssistant.class)
.streamingChatLanguageModel(streamingChatModel)
.chatMemory(messageWindowChatMemory)
.tools(toolProvider)
.retrievalAugmentor(retrievalAugmentor)
.build();
}Finally, the implementation of completion interfaces could look like the following:
@Override
public TokenStream chatTokenStream(String message) {
return streamingAssistant.chat(message);
}@Override
public String chat(String message) {
return assistant.chat(message);
}It is important to pay attention to the following:
- Assistant’s implementation in a declarative manner, like:
AiServices.builder(Assistant.class),
AiServices.builder(StreamingAssistant.class)- ToolProvider as a container of methods annotated by @Tool annotation. It’s a declarative Langchain4j concept, similar to Langchain Agent.
In Closing
To illustrate the process of going through all 5 steps explained above, let`s consider an example of using a “User Manual” of a personal financial management solution “WiseWallet”. This will demonstrate how an AI-powered Support Chatbot works.
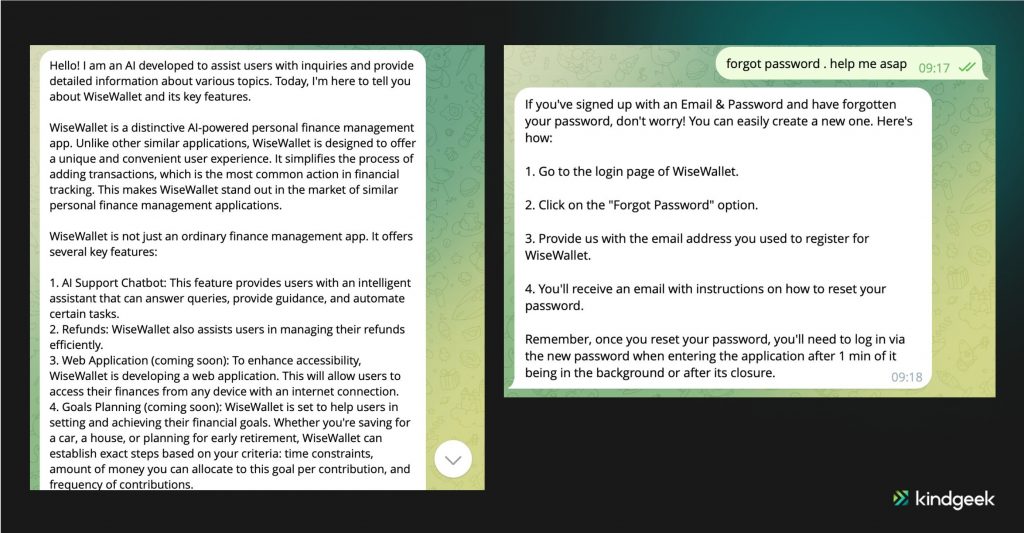
Let`s test one more thing, just for fun: Langchain4j supports Image Models (IM) like Dall-e-3. So it’s possible to add image generation features to our bot. To do this, we have to follow the next steps:
- Add configurable ImageModelBuilder extended as was shown above OpenAIChatModelBuilderParameters
@Value("${openai.imageModelName}")
String imageModelName;
@Value("${openai.image.quality}")
String imageQuality;
@Override
public ImageModel build() {
ImageModel model = OpenAiImageModel.builder()
.apiKey(OPENAI_API_KEY)
.modelName(imageModelName)
.quality(imageQuality)
.timeout(ofSeconds(timeoutSec.longValue()))
.logRequests(logRequests.booleanValue())
.logResponses(logResponses.booleanValue())
.build();
return model;
}- Add @Tool annotated code like the following:
@Tool("Draw the picture base on following description")
public URI generateImageUrl(String description) {
ImageModel model = imageModelBuilder.build();
Response<Image> response = model.generate(description);
URI uri = response.content().url();
return uri;
}As a result, our bot can generate a picture, answering a query like “draw a picture about key features of WiseWallet”.

Enjoy your journey of developing an AI-powered Telegram bot with Langchain4j in Java.
References
- https://core.telegram.org/api
- https://docs.langchain4j.dev/tutorials/
- https://github.com/langchain4j/langchain4j-examples
- https://help.openai.com/en/
- https://github.com/ollama/ollama
- https://huggingface.co/sentence-transformers
- https://arxiv.org/abs/2310.04408
- https://arxiv.org/abs/2310.05736
- https://arxiv.org/abs/2311.11045
- https://docs.cohere.com/reference/
- https://platform.openai.com/docs/api-reference/