
Recently updated on April 21, 2026
In this article, we are discussing with Michael Kramarenko, Kindgeek CTO, how to incorporate LM/LLM-based features into Java projects using Langchain4j. This framework streamlines the development of LLM-powered Java applications, drawing inspiration from Langchain, a popular Java Langchain framework that is designed to simplify the process of building applications utilizing large language models.
Join us with a cup of a great coffee, and enjoy our info-packed ten-minute read on Java way to building an LLM app with Langchain4j☕.
Brief intro or a quick reality check
Integrating LM/LLM-based functionality in existing and new products is definitely proving to be more than a mere trend. Today, embracing AI innovation is more about keeping up with the curve.
Indeed, as per Gartner analysis, Generative AI, GPT, and LM/LLM applications are becoming key driving forces in shaping IT products for the upcoming 5–10 years. And no wonder, artificial intelligence is the future. Such solutions will use features like chat but will be integrated with a corporate knowledge base, internal and external data via API, and acquired from web crawling. This article provides insights on how to use LM/LLM in Java applications effectively.
Content
- Setting the Scene or “What problem are we solving?”
- Starting from business needs, not from technological aspects
- Typical building blocks of LLM-powered application
- Starting our Langchain4j for llm journey
- User Experience aspect: delving into nuances
- Memory and state management
- Corporate data aspect or extending LLM’s knowledge
- LLM Functions and Langchain4j java @Tools
- Summing up
Setting the Scene or “What problem are we solving?”
At this point of the story let us meet our virtual character – John Geek.
He’s a tech lead of a mission-critical Java Spring-based project that has been in development for years.
Now, amidst AI advancements, the customer asks John to explore LLM integration into Java fully integrated with the essential corporate data (structured, semi-structured, and unstructured), internal and external data points accessible via REST API.

So what are the options for John?
He perfectly knows that Python is the lingua franca of AI development, not Java.
Theoretically, he could choose the “Polyglot architecture” way. However, such a way would increase the Learning Curve for John’s development team, maintenance complexity, complicate dependency management, CI/CD pipeline, testing, and deployment strategies.
It’s clear to him that the microservices architecture is technology-neutral. However, his current architecture is a modular monolith. Given this, transitioning to a microservices architecture presents significant implementation challenges. It’s an additional complication compared to the “Polyglot architecture” way.
On the other hand, John has heard about different pure Java options like
- using Java library supporting OpenAI API like Simple OpenAI
- exploring Spring AI, however the project doesn’t have public releases yet
- leveraging Java framework like Langchain4j

Starting from business needs, not from technological aspects
Enterprise-grade LLM-powered applications can be developed using various components tailored to specific business requirements. So the first step requires a deep understanding of the business case and supported use cases. This understanding, in turn, facilitates a seamless alignment of the LLM solution with the business needs, leading to the identification of critical success factors of the final deliverable. During this phase, it’s possible to refine aspects such as roles, regulations, communication strategies, and prompting procedures.
Since LLM-driven applications are inherently data-centric, you need to deeply understand your data:
- origin: external or internal data
- data type: structured, semi-structured, or unstructured data
- data source type: internal API, 3-d party API, web crawling, etc.
- data formats: html, json, pdf, doc etc.
To gain a profound understanding of use cases and corporate data, we’d highly recommend utilizing methodologies like CPMAI, CRISP-DM.
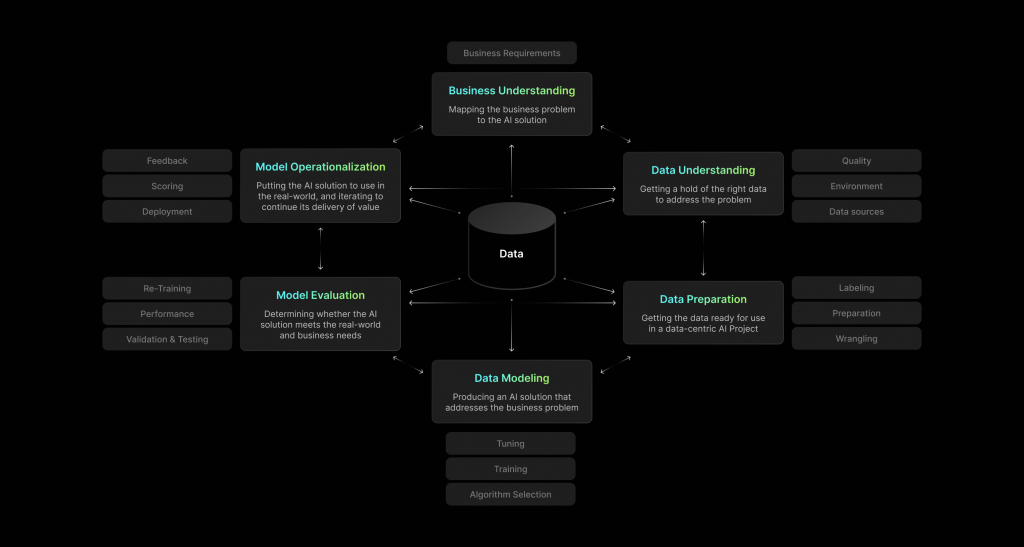
Typical building blocks of LLM-powered application
Understanding of your use cases and data allows you to produce an AI solution that addresses the business problem. So you can use different building blocks for your app:
- LM/LLM: lies at the heart of LM/LLM-driven applications, exemplified by models like GPT-3, BERT, etc. These models, offered by different LLM providers, have been trained on vast amounts of text data and can perform a variety of NLP tasks, such as text generation, summarization, translation, and question-answering.
- Prompts & Templates: inputs given to the LLM to generate a response or perform a specific task. The design of these prompts is critical, as it significantly influences the output of the model.
- Embeddings: numerical representations of words, phrases, or entire documents that convert text into a format that can be processed by LLMs to capture the semantics of the text, which aids in tasks like semantic search, text classification, and similarity comparisons.
- Vector Database: is used to store and manage embeddings. It enables efficient storage, retrieval, and comparison of these high-dimensional vectors for semantic search, where the goal is to find the most relevant pieces of text based on their semantic similarity.
- Memory and State Management: for context retention over multiple interactions
- Data Preprocessing and Normalization: involves tasks such as cleaning the data, removing irrelevant information, standardizing formats, and ensuring that the data is in a suitable form for the model to process.
- APIs and Integration Tools: for integration of LLM capabilities into applications, whether it’s for a chatbot, content creation tool, or data analysis platform.
Starting our Langchain4j journey
Before we commence our project journey, make sure to complete the following preparation steps:
- Create a Spring Boot 3.2.1 Maven project using, for example, Spring Initializr. We can start with spring-boot-starter-web
- Add Langchain4j 0.25.0 Maven dependencies. We can start our journey with langchain4j and langchain4j-open-ai
- Feel free to add other dependencies like lombok, org.slf4j, commons-io, Springdoc openapi, etc.
To use LLM in Java with Langchain4j, developers can take advantage of its predefined components and easy setup.
Within this experiment, we’ll proceed with OpenAI LLMs, so the last preparation step would involve acquiring the OpenAI API key using the api-keys page to finalize the necessary setup. This setup ensures a seamless integration of Langchain Java capabilities into your application.
Configuring your LLM-powered application
Langchain4j 0.25.0 offers numerous integrations with the following AI platforms:
| AI Platform | Deployment model | Business model | Opensource | Comments |
| OpenAI | AIaaS | usage-based pricing model | ❌ | One of the most advanced AI platforms, a vendor of multimodal LLMs like GPT-4, DALL·E, and Whisper, a versatile speech recognition model |
| Azure OpenAI | AIaaS | usage-based pricing model | ❌ | Deployment of OpenAI models into Microsoft’s Azure cloud for seamless integration with other native cloud services |
| Google Vertex AI, Vertex AI Gemini | AIaaS | usage-based pricing model | ❌ | Comprehensive, scalable platform for AI development and deployment, with access to cutting-edge Google AI technology and its integration with the broader ecosystem of Google Cloud services |
| Amazon Bedrock | AIaaS | usage-based pricing mode | ❌ | Serverless AI platform that allows building agents using top-foundation models integrated with enterprise systems and data sources |
| Huggingface | primary AIaaS | core-free, subscription-based | ✅ | Open-source project with a strong community focus, encouraging collaboration and sharing among AI researchers. |
| QwenLM | primaryAIaaS | primary usage-based pricing model | ✅ | The most simple way to use Qwen through DashScope API service of Alibaba Cloud – multimodal LLMs platform, including Qwen Audio and Qwen Audio Chat |
| LocalAI | on-premise | free | ✅ | Open-source alternative to OpenAI, designed as a drop-in replacement REST API for local inferencing |
| Ollama | on-premise | free | ✅ | Allows to run open-source large language models, such as LLaMA2, locally |
| ChatGLM-6B | on-premise | free | ✅ | Employs technology similar to ChatGPT, optimized specifically for Chinese question-answering and dialogue scenarios |
To further enhance the flexibility of our application, we will extensively employ the @Value annotation. This approach enables the efficient configuration of LLM settings and other building blocks in external files such as application.properties or application.yml.
Here’s a brief overview of OpenAI parameters supported by Langchain4j 0.25.0
| OpenAI parameter | Description |
| API key | Enables OpenAI to authenticate users and ensure that only authorized users can access the API |
| Model Version/Name | Different versions or types of models (e.g., GPT-3, GPT-3.5, GPT-4) have different capabilities, with newer versions generally offering more advanced features or larger parameter counts |
| Temperature | Controls the randomness (or “creativity”) of the model’s responses. A higher temperature results in more creative and less predictable responses, while a lower temperature produces more deterministic and potentially more accurate responses. A higher temperature increases the “hallucination” probability |
| Frequency Penalty | Reduces the model’s tendency to repeat the same word or phrase. Increasing the frequency penalty helps in generating a more diverse response |
| Presence Penalty | Being similar to the frequency penalty, this setting discourages the model from mentioning topics or entities that it has already talked about. This can be useful for keeping the conversation or content generation diverse |
| Top-P (Nucleus Sampling) | Instead of sampling only from the most likely K words, Top-p sampling chooses from the smallest possible set of words whose cumulative probability exceeds the probability p |
| Logit Bias | Employed to adjust the likelihood of certain words or phrases appearing in the model’s output. By applying a bias to the logits (the raw output scores from the model before they are converted into probabilities), you can make certain words more or less likely to be selected |
| Seed | If specified, the platform will make the best effort to sample deterministically, ensuring that repeated requests with the same seed and parameters should return the same result |
| User | Sending end-user IDs in your requests can be a useful tool to help OpenAI detect abuse, and generate more relevant and coherent responses.The IDs should be a string that uniquely identifies each user |
| Response Format | Format “json_object” guarantees a model respond as a valid JSON |
Indeed, mind that LangChain4j offers up its own specific settings, which prove to be very useful for our further experiments:
| API Timeout | Log API request | Log API response |
| Regulate the time limit for API requests to ensure prompt responsiveness | Choose to log details of LLM API requests to facilitate debugging processes. | Opt to log API response details, aiding in the analysis of model outputs and troubleshooting potential issues. |
It is worth noting that Langchain4j primarily utilizes the Builder pattern with numerous parameters.
As a result, our application could contain several externally configurable Builders inherited from abstract class like ChatModelBuilderParameters:
@Slf4j
public abstract class ChatModelBuilderParameters {
@Value("${OPENAI_API_KEY}")
String OPENAI_API_KEY;
@Value("${GPT.modelName}")
String gptModelName;
@Value("#{new Boolean('${openai.log.requests}')}")
Boolean logRequests;
@Value("#{new Boolean('${openai.log.responses}')}")
Boolean logResponses;
@Value("#{new Long ('${openai.timeout.sec}')}")
Long timeoutSec;
@Value("#{new Double ('${openai.temperature}')}")
Double temperature;
}
In such a case, a corresponding ChatModelBuilder could look like this:
@Service
@Slf4j
public class ChatLanguageModelBuilder extends ChatModelBuilderParameters
implements ChatModelBuilder {
@Value("#{new Integer ('${openai.maxRetries}')}")
Integer maxRetries;
@Override
public ChatLanguageModel build() {
ChatLanguageModel chatLanguageModel = OpenAiChatModel.builder()
.apiKey(OPENAI_API_KEY)
.modelName(gptModelName)
.timeout(ofSeconds(timeoutSec.longValue()))
.logRequests(logRequests.booleanValue())
.logResponses(logResponses.booleanValue())
.maxRetries(maxRetries)
.temperature(temperature)
.build();
return chatLanguageModel;
}
}
User Experience aspect: delving into nuances
Indeed, the traditional approach involves standard Spring MVC, characterized by a blocking model of “request-response.”
However, Spring Boot also embraces a non-blocking, asynchronous model.
Particularly, Spring WebFlux is a reactive web framework built on reactive streams. And it’s exactly what we are looking for.

In WebFlux, a stream (sequence of data sent from one system to another) is processed in a non-blocking reactive manner, meaning that the system can respond to changes and events in real-time, ensuring it can handle data as it arrives without the need for blocking or sequential processing.
This approach enables a more dynamic and responsive system, allowing for concurrent processing of incoming data streams:

Here is an example of what the code for an image generation might look like:
- the first step – build ImageModel using Builder like ImageModelBuilder
- the next step – generate an image based on the scene description
@Slf4j
public class ImageModelBuilderImpl extends ChatModelBuilderParameters implements ImageModelBuilder {
@Value("${openai.imageModelName}")
String imageModelName;
@Value("${openai.image.quality}")
String imageQuality;
@Override
public ImageModel build() {
ImageModel model = OpenAiImageModel.builder()
.apiKey(OPENAI_API_KEY)
.modelName(imageModelName)
.quality(imageQuality)
.timeout(ofSeconds(timeoutSec.longValue()))
.logRequests(logRequests.booleanValue())
.logResponses(logResponses.booleanValue())
.build();
return model;
}
}
@Override
public URI generateImageUrl(String description) {
log.debug("Generating image for : {} ", description);
Response<Image> response = model.generate(description);
URI uri = response.content().url();
log.debug("Generated image URI : {} ", uri);
return uri;
}
Memory and state management
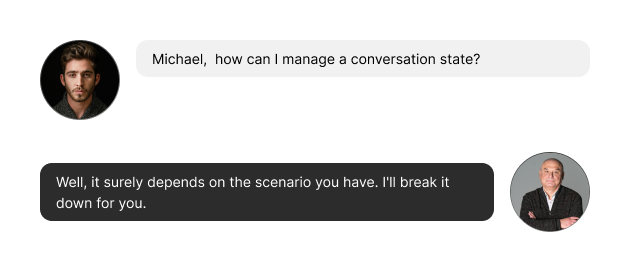
For a simple scenario, you have two options: TokenWindowChatMemory, and MessageWindowChatMemory.
TokenWindowChatMemory operates as a sliding window of maxTokens tokens. It retains as many of the most recent messages as can fit into the window. If there isn’t enough space for a new message, the oldest one (or multiple) is discarded.
MessageWindowChatMemory operates as a sliding window of maxMessages messages. It retains as many of the most recent messages as can fit into the window. If there isn’t enough space for a new message, the oldest one is discarded.
For more complex scenarios, you can decide how chat memory is stored, and use your implementation of ChatMemoryStore interface.
You can also use @MemoryId annotation to find the memory tied to a given user/conversation.
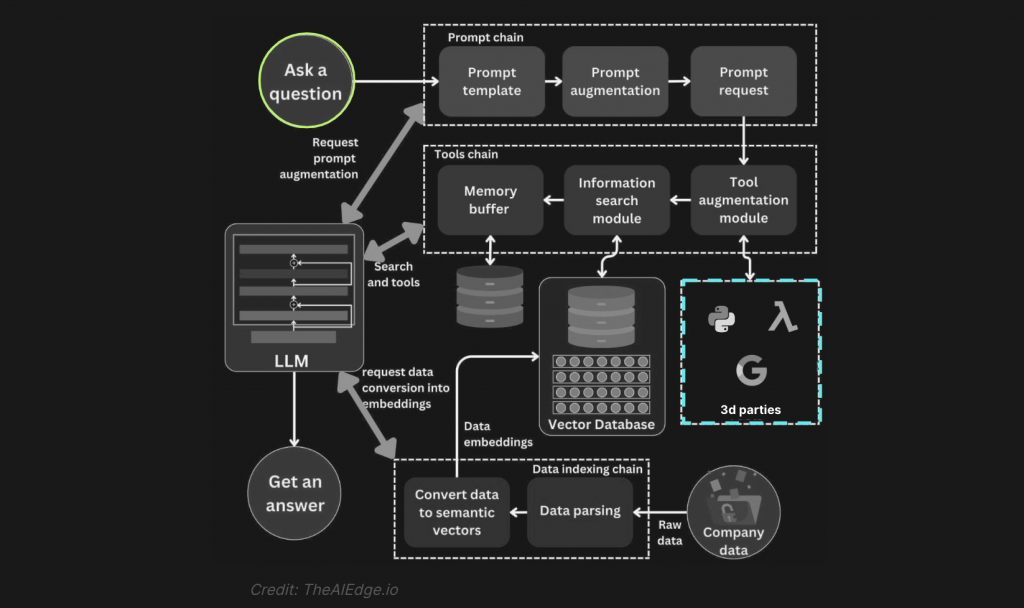
Corporate data aspect or extending LLM’s knowledge
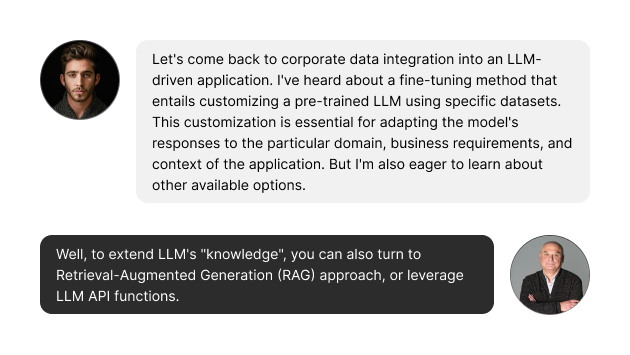
To extend LLM’s “knowledge”, you can use Retrieval-Augmented Generation (RAG), or leverage LLM API functions.
RAG is designed to enhance the ability of LLMs to provide more accurate and relevant responses by supplementing its pre-trained knowledge with information retrieved from a large corpus of documents (rather unstructured data), like corporate knowledge base or external data achievable via Web crawling.
Another option for answering factual questions when detailed, specific knowledge is required is using LLM API functions. Indeed, certain LLMs have been fine-tuned to detect when a function should be called and respond with the inputs that should be passed to the function. In such a way, an application can be integrated with external APIs.
RAG approach
Similar to Langchain, Langchain4j provides all the building blocks for RAG applications:
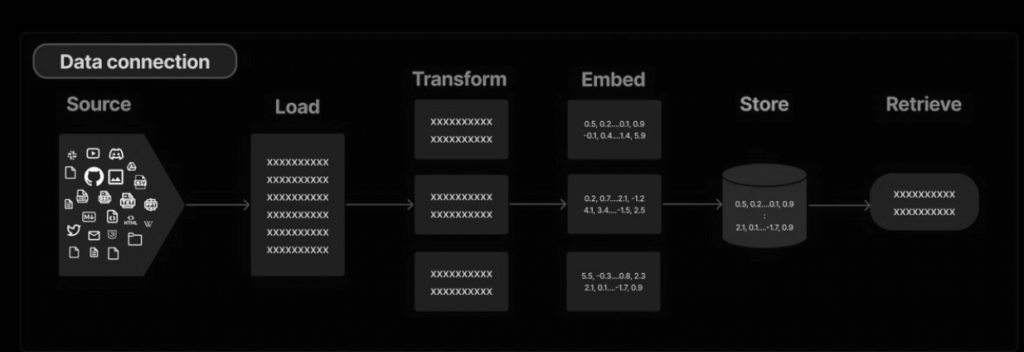
The first step of the RAG chain is document loading. Langchain4j provides DocumentLoader for loading documents (using Document representation) from many sources (private S3 buckets, public websites, filesystem) in different formats (text, HTML, PDF, Microsoft documents).

It is important to note that in HTML case, we need to clear markup using HtmlTextExtractor ,so our code could look like this:
public Document extractHtmL(String urlString) {
URL url = formUrl(urlString);
Document htmlDocument = UrlDocumentLoader.load(url, newTextDocumentParser());
HtmlTextExtractor transformer = new HtmlTextExtractor(null, null, true);
Document transformedDocument = transformer.transform(htmlDocument);
return transformedDocument;
}
Also, you can use HtmlTextExtractor as an HTML markup filter via specific CSS selectors.
A key part of retrieval is fetching only the relevant parts of documents. The next step is splitting (or chunking) a Document into smaller chunks using DocumentSplitter recursive(int maxSegmentSizeInTokens, int maxOverlapSizeInTokens, Tokenizer tokenizer)
The last step of document loading is the ingestion of documents into an embedding store. It manages the entire pipeline process, from splitting the documents into text segments, generating embeddings for them using a provided embedding model, and finally storing them in a vector database.

Embeddings are condensed numerical representations of words, phrases, and entire documents that capture their semantic meaning and context and are expressed as vectors in a high-dimensional space.
These vectors of floating point numbers are what LLMs normally process to grasp semantic and syntactic relationships between words. Small distances between vectors suggest high semantic relevance, while large distances imply low semantic relevance. By assessing the distance between these embedding vectors (cosine similarity), we can learn what is semantically “the closest” to other content.
Embedding models in LangChain4j
In Langchain4j, embedding models corresponding to specific LLM are represented by specific classes (like OpenAiEmbeddingModel, Hugging Faces AllMiniLmL6V2EmbeddingModel, LocalAiEmbeddingModeletc.). For example, Hugging Faces all-MiniLM-L6-v2 model maps sentences & paragraphs to a 384-dimensional dense vector space and can be used for tasks like clustering or semantic search.
Vector Databases in LangChain4j
Langchain4j supports a broad selection of Vector databases for efficient storage of embeddings:
| Vector DB Type | Vector DB |
| Pure vector databases | Chroma , Milvus , Pinecone , Vespa , Weaviate |
| Full text search datastor | Elastic Search , Open Search |
| Vector-capable NoSQL databases | Cassandra, Astra DB, Redis, Neo4j, |
| Vector-capable SQL databases | Pgvector extension for Postgresql (ver.11+) |
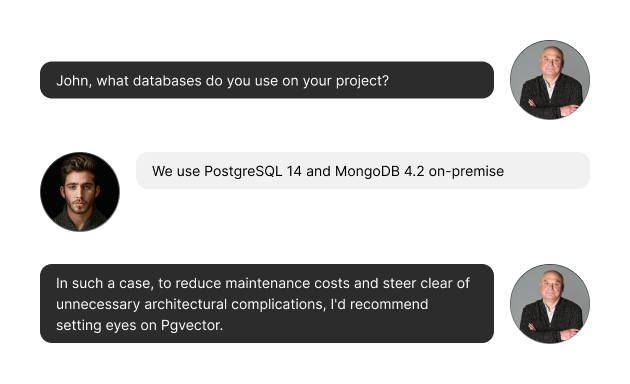
After Pgvector extension installation (via CREATE EXTENSION vector), you will be able to use vector type and vectors table:
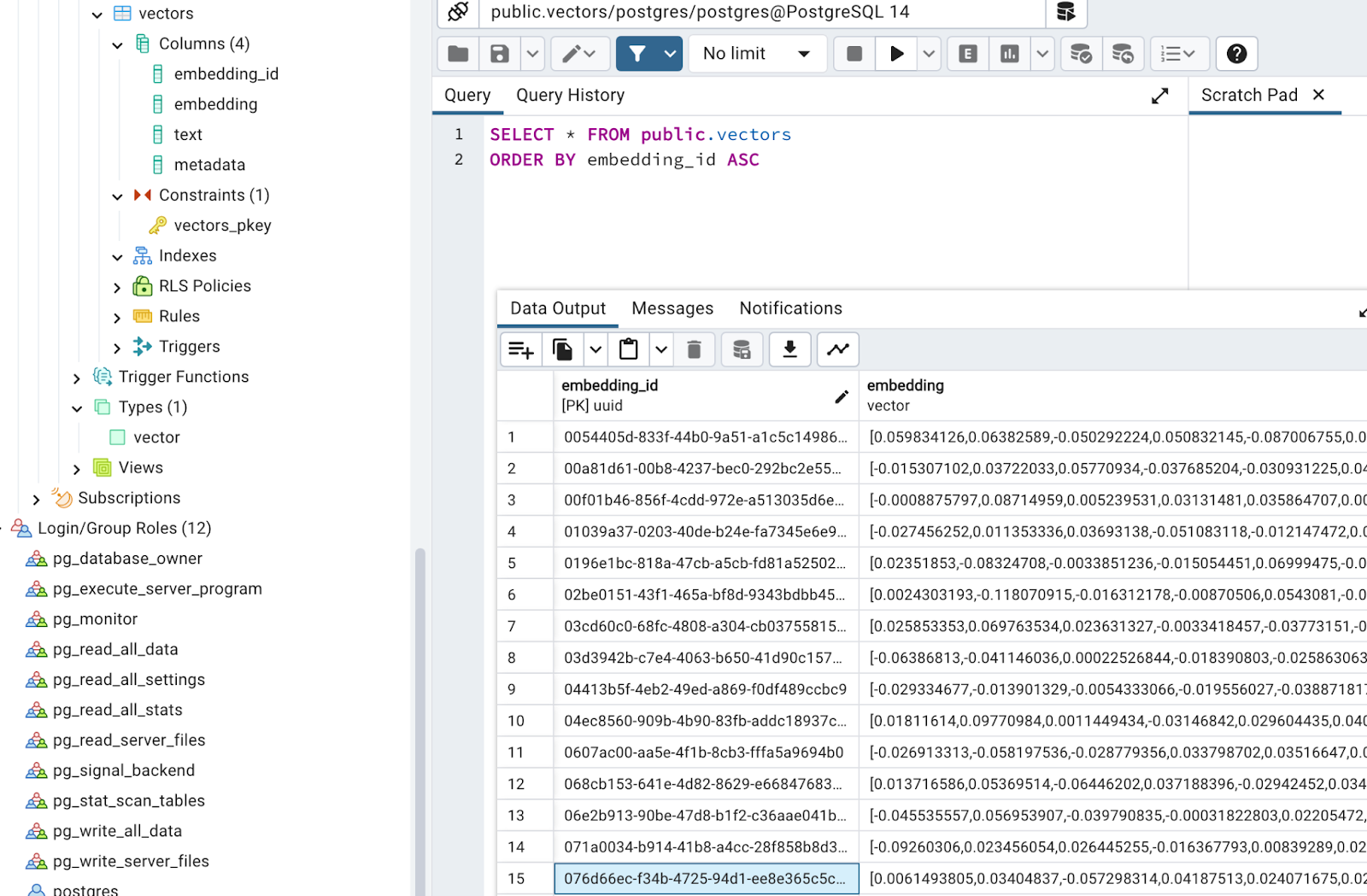
As a result, HTML document loading and ingesting process can be implemented in the following way:
@Override
public LoadHtmlDocumentDto loadHtmlDocument(String urlString, Integer maxSegmentSize, Integer maxOverlapSize) {
log.debug("Loading document from: {} maxSegmentSize {} maxOverlapSize {}", urlString, maxSegmentSize, maxOverlapSize);
EmbeddingStore<TextSegment> pgVectorEmbeddingStore = embeddingStoreServiceBuilder.build();
HtmlLoader loader = new HtmlTextLoader();
Document document = loader.extractHtmL(urlString);
EmbeddingModel embeddingModel = new AllMiniLmL6V2EmbeddingModel();
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.documentSplitter(DocumentSplitters.recursive(maxSegmentSize, maxOverlapSize))
.embeddingModel(embeddingModel)
.embeddingStore(pgVectorEmbeddingStore)
.build();
ingestor.ingest(document);
LoadHtmlDocumentDto documentDto = new LoadHtmlDocumentDto(urlString, maxSegmentSize, maxOverlapSize);
log.debug("Ingested document: {}", documentDto);
return documentDto;
}
Retrieval chain can be implemented the following way:
@Override
public ConversationalRetrievalChain build() {
EmbeddingStore<TextSegment> pgVectorEmbeddingStore = embeddingStoreServiceBuilder.build();
EmbeddingModel embeddingModel = new AllMiniLmL6V2EmbeddingModel();
ChatLanguageModel chatLanguageModel = chatLanguageModelBuilder.build();
TokenWindowChatMemory selfExplainMemory = chatMemoryBuilder.build();
ConversationalRetrievalChain chain = ConversationalRetrievalChain.builder()
.chatLanguageModel(chatLanguageModel)
.retriever(EmbeddingStoreRetriever.from(pgVectorEmbeddingStore, embeddingModel))
.chatMemory(selfExplainMemory)
.build();
return chain;
}
Besides, mind adding Langchain4j Pgvector and Langchain4j Embeddings-all-minilm-l6-v2 dependencies in your Maven build.

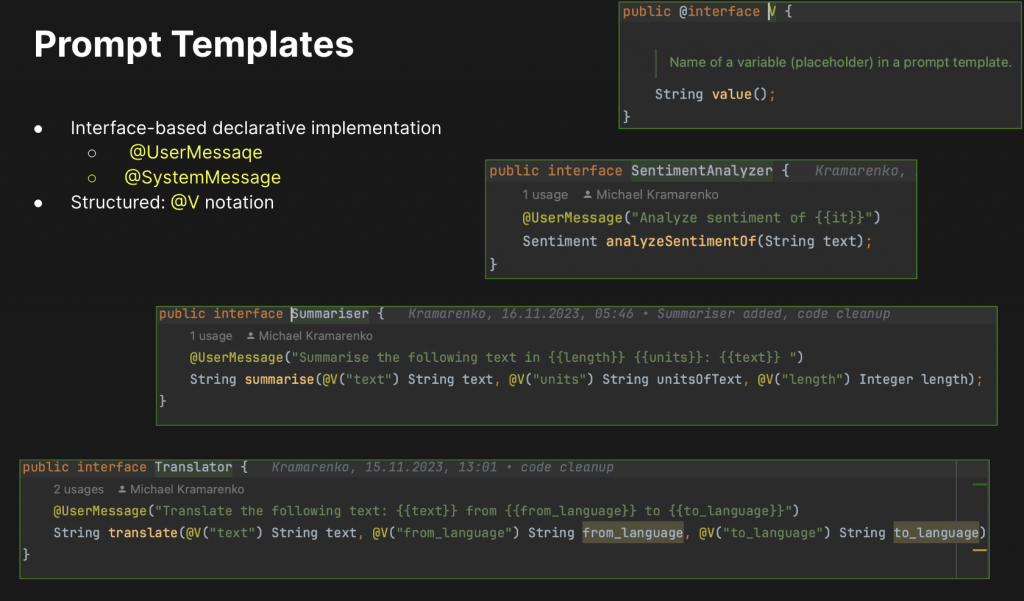
But essentially, a significant point here is the evaluation of translation quality.
For that, we could use the following approach:
- Mark an original web-crawled content as an original document written in some original language
- Mark translated content as a translated document in a corresponding translation language
- Introduce some threshold semantic distance between original and translated content.
Here, we might also use direct and reverse translation, and calculate a semantic distance between the original and the reverse-translated documents.
By employing such a threshold, we would be able to highlight the documents for further manual correction of translation.
As a result, our code can look as follows:
- Prompt-template base Translator interface
public interface Translator {
@UserMessage("Translate the following text: {{text}} from {{from_language}} to {{to_language}}")
String translate(@V("text") String text, @V("from_language") String from_language, @V("to_language") String to_language);
}
- Declarative Translator implementation
Translator translator = AiServices.builder(Translator.class)
.chatLanguageModel(chatLanguageModel)
.chatMemory(memory)
.build();
- Direct and reverse translation with cosine similarity calculation
@Override
public TranslationDto translate(String text, String from_language, String to_language) {
log.debug("\nTranslating text : {} from {} to {} ", text, from_language, to_language);
String translatedText = translator.translate(text, from_language, to_language);
log.debug("\nTranslation result: {} ", translatedText);
String reverseTranslatedText = translator.translate(translatedText, to_language, from_language);
log.debug("\nReverse Translation text : {} from {} to {} ", reverseTranslatedText, to_language, from_language);
EmbeddingModel embeddingModel = new AllMiniLmL6V2EmbeddingModel();
Embedding embeddingInput = embeddingModel.embed(text).content();
Embedding embeddingReverseTranslation = embeddingModel.embed(reverseTranslatedText).content();
Double cosineSimilarity = CosineSimilarity.between(embeddingInput, embeddingReverseTranslation);
TranslationDto translationDto = new TranslationDto(from_language, text, to_language, translatedText, reverseTranslatedText, cosineSimilarity);
return translationDto;
}
It is worth to note, that we can ingest original and translated documents as well their summarization using declarative Summariser implementation:
public interface Summariser {
@UserMessage("Summarise the following text in {{length}} {{units}}: {{text}} ")
String summarise(@V("text") String text, @V("units") String unitsOfText, @V("length") Integer length);
}
Summariser summariser = AiServices.builder(Summariser.class)
.chatLanguageModel(chatLanguageModel)
.build()
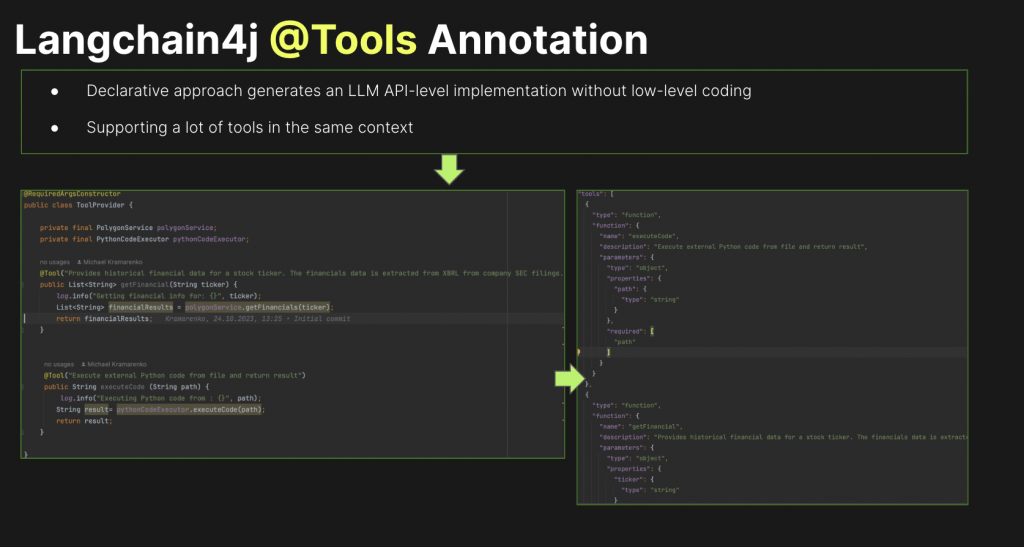
LLM Functions and Langchain4j @Tools

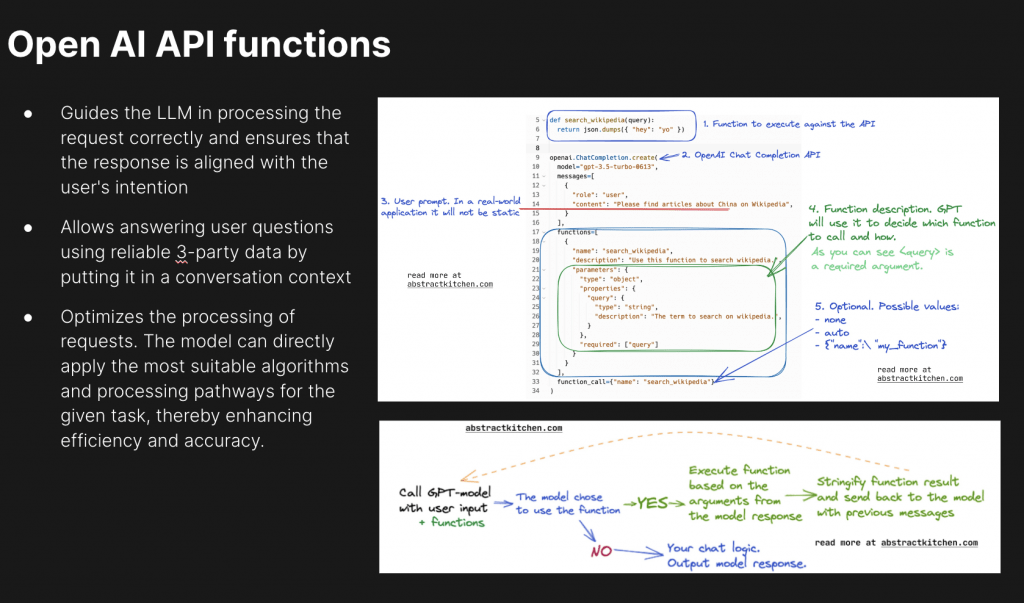
Langchain4j utilizes a declarative approach via @Tool annotation, providing an easier and more efficient “function” integration way.
Langchain4j @Tool concept is very similar to Langchain Agent which can be thought of as an intermediary that is responsible for orchestrating the flow of information and maintaining the efficiency and effectiveness of the language model within the application context. So, we can wrap a third-party REST API as a Langchain4j @Tool.
Historical Stock Data via REST API
Let’s illustrate this approach step-by-step with an example of Polygon.io REST API, assuming that our application should provide historical stock data for a given stock ticker. We will use API-endpoint, which provides financial XBRL-data from company SEC filings including equity, audited financial statements, and other relevant information.
- The first step is obtaining JSON using the following PolygonRestClient, parsing it, and converting it to an object that will be used in a function execution context (List<String> in our example):
public List<String> getFinancials(String ticker) throws Exception {
RestTemplate restTemplate = new RestTemplate();
ResponseEntity<String> response
= restTemplate.getForEntity(formUrl(ticker), String.class);
String financialJson = response.getBody();
log.trace("Json: {}", financialJson);
ObjectMapper mapper = new ObjectMapper();
JsonFactory factory = mapper.getFactory();
// to prevent exception when encountering unknown property:
mapper.disable(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES);
// to allow coercion of JSON empty String ("") to null Object value:
mapper.enable(DeserializationFeature.ACCEPT_EMPTY_STRING_AS_NULL_OBJECT);
JsonParser parser = factory.createParser(financialJson);
JsonNode root = mapper.readTree(parser);
Map<String, Object> map = mapper.treeToValue(root, Map.class);
List<String> resultList = convert(map);
return resultList;
}
The next step is a wrapping of low-level PolygonRestClient by PolygonService implementation like code below:
public List<String> getFinancials(String ticker) {
List<String> resultList;
try {
resultList = polygonRestClient.getFinancials(ticker);
return resultList;
} catch (Exception e) {
log.error("API error", e);
}
return null;
}
- The last step is an adding @Tool annotation to
public class ToolProvider {
private final PolygonService polygonService;
@Tool("Provides historical financial data for a stock ticker. The financials data is extracted from XBRL from company SEC filings. Provides the following information: Balance sheet, Income statement, Statement of comprehensive Income, Cash flow statement, ")
public List<String> getFinancial(String ticker) {
log.info("Getting financial info for: {}", ticker);
List<String> financialResults = polygonService.getFinancials(ticker);
return financialResults;
}
As a result, the following function definition will be used for answering a user query like “provide financial analysis for a ticker IBM”:
"tools": [
"type": "function",
"function": {
"name": "getFinancial",
"description": "Provides historical financial data for a stock ticker. The financials data is extracted from XBRL from company SEC filings. Provides the following information: Balance sheet, Income statement, Statement of comprehensive Income, Cash flow statement, ",
"parameters": {
"type": "object",
"properties": {
"ticker": {
"type": "string"
}
},
"required": [
"ticker"
]
}
}
}
]In such a case, LLM answer in a log file will be similar for the next one:

Finally, let’s get back to the aforementioned point about “Polyglot architecture”. The recent Langchain4j integration with Graalvm Polyglot supports code execution written in Python and JavaScript code execution.
As a result, we can wrap a Python code as a @Tool as follows:
@Tool("Execute external Python code from file and return result")
public String executeCode (String path) {
log.info("Executing Python code from : {}", path);
String result= pythonCodeExecutor.executeCode(path);
return result;
}
A PythonCodeExecutor can look like:
public class PythonCodeExecutor implements CodeExecutor{
@Override
public String executeCode(String path) {
log.debug(" Loading code from file {}" , path );
String pyCode= PythonCodeLoader.fromResourceFile(path);
log.debug("\n Code: {}", pyCode);
CodeExecutionEngine engine = new GraalVmPythonExecutionEngine();
String result = engine.execute(pyCode);
log.debug("\n Code execution result : {}", result);
return result;
}
}
Let’s assume that we have some Python code stored on the external file code/python/fibonacci.py:
def fibonacci(n):
if n <= 1:
return n
else:
return fibonacci(n-1) + fibonacci(n-2)
fibonacci(10)
In such a case, a user query like “execute a code in code/python/fibonacci.py” will be answered like this:
"model": "gpt-4-1106-preview",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The code in the file `code/python/fibonacci.py` has been executed successfully, and the result is `55`. This likely means that the code was designed to calculate a specific Fibonacci number, and the result of the calculation is 55."
},
"logprobs": null,
"finish_reason": "stop"
}
],
Just for fun – we can also wrap our ImageModel as @Tool in the following way:
@Tool( "Draw the picture base on following description")
public URI generateImageUrl(String description) {
log.debug("Generating image for : {} ", description);
Response<Image> response = model.generate(description);
URI uri = response.content().url();
log.debug("Generated image URI : {} ", uri);
return uri;
}
In such a case, a user query like “draw a picture about fibonacci” will be answered like this:
"message": {
"role": "assistant",
"content": "A picture representing the Fibonacci sequence with spirals and numbers has been created. You can view the image by clicking on the link below:\n\n
Summing up
LangChain4j stands out as a still young but promising framework tailored for LLM-driven application development in Java.
It connects various ready-to-use building blocks: LLMs themselves, document loaders, parsers, vector stores, tools, conversational chains, and prompt templates.

Here is what we would like to highlight about Langchain4j framework:
- Higher abstraction level compared with LLMs API level
- No LM/LLM vendor/platform lock-in. As a result, Enabling AIaaS as on-premise LLMs usage
- No Vector databases vendor lock-in
- Supporting different deployment scenarios
- In-built document transformation pipeline that supports the most popular document formats and data storages
- Declarative application development approach: interface-based and annotation-based implementation